
Submitted to ICASSP 2023.
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, and Douglas Eck. "Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset." In International Conference on Learning Representations, 2019.
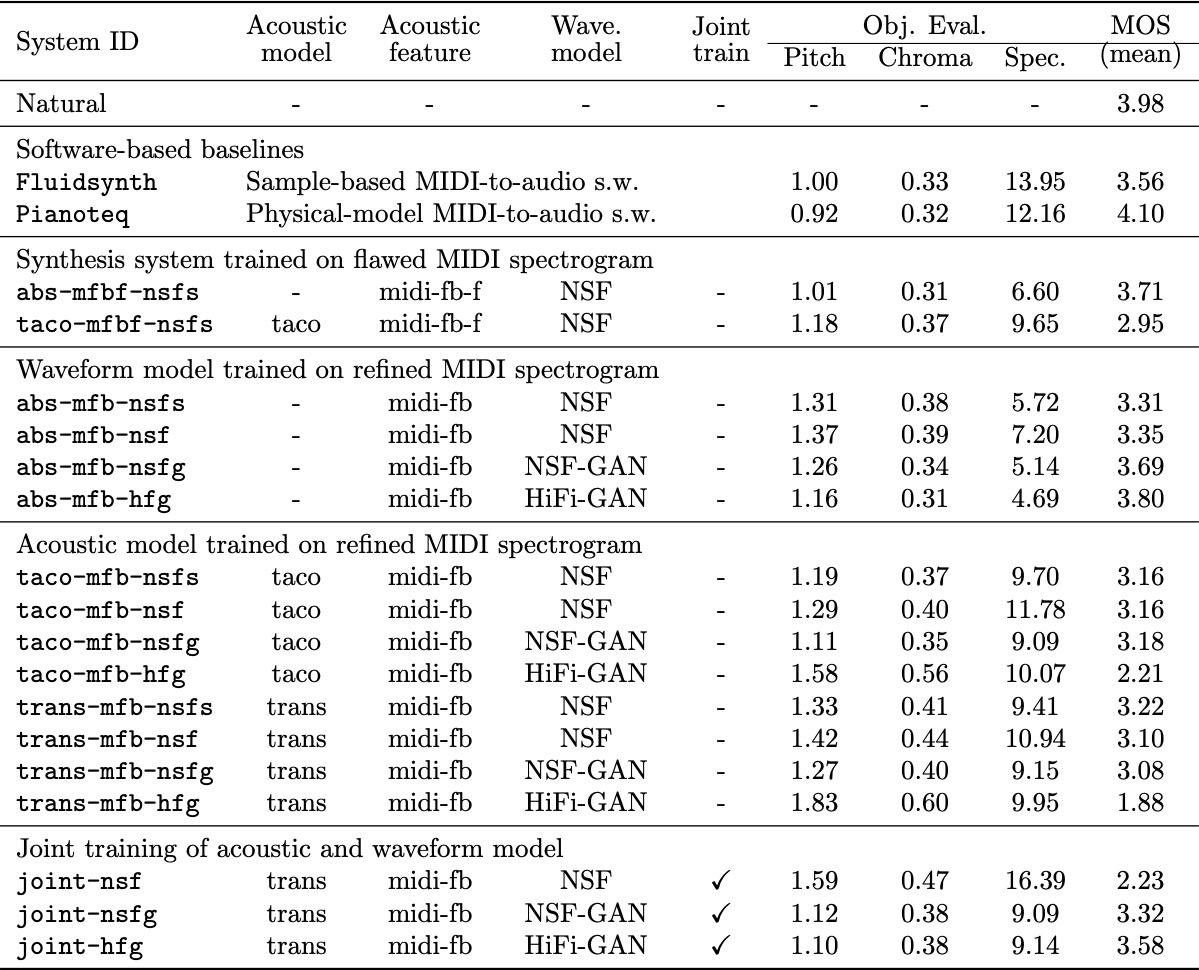
| Natural | |||
| Fluidsynth | |||
| Pianoteq | |||
| abs-mfbf-nsfs | |||
| taco-mfbf-nsfs | |||
| abs-mfb-nsfs | |||
| abs-mfb-nsf | |||
| abs-mfb-nsfg | |||
| abs-mfb-hfg | |||
| taco-mfb-nsfs | |||
| taco-mfb-nsf | |||
| taco-mfb-nsfg | |||
| taco-mfb-hfg | |||
| trans-mfb-nsfs | |||
| trans-mfb-nsf | |||
| trans-mfb-nsfg | |||
| trans-mfb-hfg | |||
| joint-nsf | |||
| joint-nsfg | |||
| joint-hfg |