Joint Workshop of VoicePersonae and ASVspoof 2023
 The image is generated using DALL-E “futuristic city of tokyo japan, shibuya crossing, illustration painting, voice, face, overdetailed digital art”.
The image is generated using DALL-E “futuristic city of tokyo japan, shibuya crossing, illustration painting, voice, face, overdetailed digital art”.
21-22 November, 2023, Hitotsubashi, Tokyo, Japan
We are excited to have all of you brilliant researchers back to in-person mode, at Hitotsubashi, Tokyo, the heart of the grand city!
For questions, please contact voicepersonaeworkshop@nii.ac.jp.
- Introduction
- Important Dates
- Call for Presentations
- Registration[CLOSED]
- Technical Program at a Glance
- Venue and Lunch Map
- Organizers and Acknowledgement
Introduction
This joint workshop is a summary initiative between two projects that have been driving the research of voice biometric identification.
- VoicePersonae aims to break down the barriers within the field of voice identity, and develop new techniques for privacy protection, security, and generative modeling of voice identities.
- ASVspoof aims to provide benchmarking solutions to foster the development of countermeasures (CMs) to protect against the manipulation of ASV systems from spoofing attacks.
Important Dates
All dates listed below follow Anywhere on Earth unless noted.
Submission portal opens: Aug. 18th, 2023Deadline of CFP submission: Oct. 6th, 2023Notification of acceptance: Oct. 20th, 2023Deadline of Registration (requiring an invitation letter): Oct. 27th, 2023Deadline of Registration: Nov. 6th, 2023- VoiceMOS mini workshop: Nov. 20th [JST Time]
- VoicePersonae Workshop: Nov. 21st [JST Time]
- ASVspoof Workshop: Nov. 22nd [JST Time]
Call for Presentations
The programme kindly welcomes presentations from international speakers, covering areas of speaker recognition, speaker anonymization, speech synthesis, and spoofing detection. The workshop expects the presentation to be compact, specialized, and informative.
Please carefully read the information below for preparing the submitting your proposal of presentation.
- Duration: Each talk will have a duration of ~20 minutes, plus a ~5-minute Q&A and a ~5-minute break between the talks.
- Submission: Please find the link to the form below. Please find the link of form below. The title, abstract and outline of the talk can be entered in the form.
The proposals will be peer-reviewed by the technical committee. The titles of selected proposals will be posted in this page shortly after releasing the results.
Proposers of selected talks are warmly invite and encouraged to give the talk in person at Tokyo.
Registration[CLOSED]
This workshop has no registration fee and we welcome registrations and participation from people who do not have presentations, with two things noted:
- The participants should self-fund their travel and living costs at Tokyo.
- Attendance is subject to the entry regulations of the Japanese government. In such case, the participants should self-fund their visa application fee (and similar costs).
Link to registration
(Deadline: Nov. 6th 2023)
Please register before
Oct. 27th 2023 if you need an invitation letter. Thank you for your cooperation!
Technical Program at a Glance
Download detailed technical program books for
VoicePersonae (Day 1) and
ASVspoof
(Day 2).

Day 0: VoiceMOS mini workshop (November 20th): Satellite event open to anyone.
Room 101-103, Ground Floor
3:00-3:20 PM: Feedback from VoiceMOS Challenge 2023
Speakers: Dr. Erica Cooper (National Institute of Informatics, Japan) & Mr. Wen-Chin Huang (Nagoya University, Japan)
3:20-3:40 PM: Dynamic Optimization for Large-Scale Preference-based Subjective Evaluation Using Crowdsourcing
Speakers: Dr. Yusuke Yasuda (Nagoya University, Japan)
3:40-4:00 PM: Data Selection for Text-to-speech with Feedback from Automatic Evaluation of Naturalness on Synthetic Speech
Speakers: Mr. Kentaro Seki (The University of Tokyo, Japan)
4:00-4:20 PM: Self-Supervised Learning MOS Prediction with Listener Enhancement
Speakers: Dr. Sheng Li (National Institute of Information & Communications Technology, Japan)
4:20-5:00 PM: Free discussions on the contents and data for the next edition of the VoiceMOS Challenge
Day 1: VoicePersonae Workshop (November 21st)
Room 101-103, Ground Floor
-
Session 1. Chair: Prof. Nicholas Evans
10:00-11:00 AM: Opening - Overview of the VoicePersonae project
Speaker: Prof. Junichi Yamagishi (National Institute of Informatics, Japan)
11:00-11:15 AM: Short Break Time
-
Session 2. Chair: Prof. Junichi Yamagishi
11:15-11:50 AM: Voice Privacy Processing
Speaker: Prof. Jean-Francois Bonastre (Inria & Avignon University, France)
12:00-12:30 PM: Voice Biometrics & Deepfake Detection
Speaker: Prof. Nicholas Evans (EURECOM, France)
Theme 1: Speech generative models and related topics
-
Session 3. Chair: Dr. Hemlata Tak
2:00-2:30 PM: From DSP and DNN to DNN/DSP: Neural speech waveform models and its applications in speech and music audio waveform modelling
Speaker: Dr. Xin Wang (National institute of Informatics, Japan)
2:30-3:00 PM: End-to-end speech synthesis and its entertainment applications: Rakugo modeling & Musical instrument sound modeling
Speakers: Dr. Shuhei Kato (Revcomm, Japan) & Dr. Yusuke Yasuda (Nagoya University, Japan) & Dr. Erica Cooper (National Institute of Informatics, Japan)
3:00-3:30 PM: From Human Ears to Deep Neural Networks: Automatic Evaluation of Synthetic Speech and Audio Data
Speakers: Dr. Erica Cooper (National Institute of Informatics, Japan) & Mr. Wen-Chin Huang (Nagoya University, Japan)
3:30-3:45 PM: Short Break Time
Theme 2: Speech security and deepfake detection
-
Session 4. Chair: Dr. Erica Cooper
3:45-4:15 PM: From Artefacts to Insights: A Topical Analysis of Voice Biometric Security
Speakers: Prof. Massimiliano Todisco (EURECOM, France) & Dr. Hemlata Tak
4:15-4:45 PM: "Whether and When": Detection and Localization of Partially Spoofed Audio
Speakers: Ms. Lin Zhang (National Institute of Informatics, Japan)
4:45-5:15 PM: From Deepfake Detection and Segmentation to Restoration: Protection of Facial Biometrics from Manipulative and Generative AI
Speakers: Dr. Huy H.Nguyen (National Institute of Informatics, Japan) & Dr. C.C. Chang (National Institute of Informatics, Japan)
5:15-5:30 PM: Short Break Time
Theme 3: Speech privacy and speaker anonymization
-
Session 5. Chair: Dr. Xin Wang
5:30-6:00 PM: Preserving Speaker’s Privacy and Utility: The VoicePrivacy Progress and VoxCeleb2 Database anonymization
Speakers: Dr. Natalia Tomashenko (Avignon University, France) & Dr. Xiaoxiao Miao (Singapore Institute of Technology, Singapore)
6:00-6:10 PM: CLOSING
Day 2: ASVspoof Workshop (November 22nd)
Room 101-103, Ground Floor
-
Session 6. Chair: Dr. Xuechen Liu
9:30-10:20 AM: Voice, Privacy and Adversary
Speaker: Prof. Kong Aik Lee (Hong Kong Polytechnic University, Hong Kong)
10:20-10:50 AM: Audio Watermarking for Deepfake Detection: Its Premises and Limitations
Speaker: Dr. Elie Khoury (Pindrop, USA)
10:50-11:00 AM: Short Break Time
-
Session 7. Chair: Prof. Massimiliano Todisco
11:00-11:30 AM: Privacy-Preserving Method for Speech and Speaker Classification
Speaker: Prof. Sayaka Shiota (Tokyo Metropolitan University, Japan)
11:30-12:00 PM: Introduction to Highly Compressed Generalized Deepfake Detection Methods, and Deepfake Video-Audio Dataset Generation Research
Speaker: Prof. Simon Woo (Sungkyunkwan University, South Korea)
12:00-12:30 PM: Self-distilled self-supervised speaker representation learning
Speaker: Mr. Zhengyang Chen (Shanghai Jiao Tong University, China)
-
Session 8. Chair: Ms. Lin Zhang
2:00-2:50 PM: Tandem Evaluation of Countermeasures and Biometrics Comparators
Speaker: Prof. Tomi Kinnunen (University of Eastern Finland, Finland)
2:50-3:20 PM: Synthetic Speech in Forensics and Law Enforcement: Challenges and Opportunities
Speaker: Dr. Finnian Kelly (Oxford Wave Research LTD, UK)
3:20-3:30 PM: Short Break Time
-
Session 9. Chair: Prof. Jean-Francois Bonastre
3:30-4:20 PM: Harnessing Speech Data for Improved Speech Spoofing Countermeasures
Speaker: Dr. Xin Wang (National Institute of Informatics, Japan)
4:20-4:50 PM: AdvSV: An Over-the-Air Adversarial Attack Dataset for Speaker Verification
Speaker: Prof. Zhizheng Wu (Chinese University of Hong Kong, Shenzhen, China)
4:50-5:00 PM: Short Break Time
-
Session 10. Chair: Mr. Chang Zeng
5:00-5:30 PM: Adversarial Attacks on Spoofing Countermeasures
Speaker: Dr. Long Nguyen-Vu (School of Electronic Engineering, Soongsil University, South Korea)
5:30-6:00 PM: Graph Signal Processing based Representation Learning and Factorized Device Information for Anti-spoofing
Speaker: Dr. Longting Xu (Donghua University, China)
6:00-6:30 PM: Open discussions (Vote on the Topics.)
Moderator: Prof.Junichi Yamagishi
Panelists: Dr. Elie Khoury, Dr. Finnian Kelly, Prof. Jean-François Bonastre, Prof. Tomi Kinnunen
Day 3: Public Holiday (November 23rd)
Day 4: (November 24th)
Room 1903, 19F
Theme 1: Applications using neural speaker embeddings
- Time: 10 AM - 12 PM
Automatic Linking of Speaker and Text Embeddings
Speaker: Dr. Xuechen Liu (National Institute of Informatics, Japan)
Target Speaker Extraction Using Speaker Embeddings and Its Curriculum Learning
Speaker: Mr. Yun Liu (National Institute of Informatics, Japan)
Use of Speaker Recognition Approaches for Learning and Evaluating Embedding Representations of Musical Instrument Sounds
Speaker: Ms. Xuan Shi (University of Southern California, United States)
Theme 2: NII International Interns and Their Research Introduction
- Time: 3:30PM - 6:00PM
Overview of NII and NII’s International Exchange (See here)
Speaker: Prof. Emmanuel Planas (NII GLO Acting Director)
Decoding Heard, Spoken, and Imagined Speech from the Brain: An Overview, Advances in State-of-the-Art, and Future Possibilities
Speaker: Mr. Scott Wellington (University of Bath, United Kingdom)
A Unified Probabilistic Perspective on Dimensionality Reduction
Speaker: Mr. Aditya Ravuri (University of Cambridge, United Kingdom)
Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-Supervised Discrete Speech Representations
Speaker: Mr. Cheng Gong (Tianjin University, China)
Attention-based Encoder-Decoder End-to-End Neural Diarization
Speaker: Mr. Zhengyang Chen (Shanghai Jiao Tong University, China)
How to Access the Venue
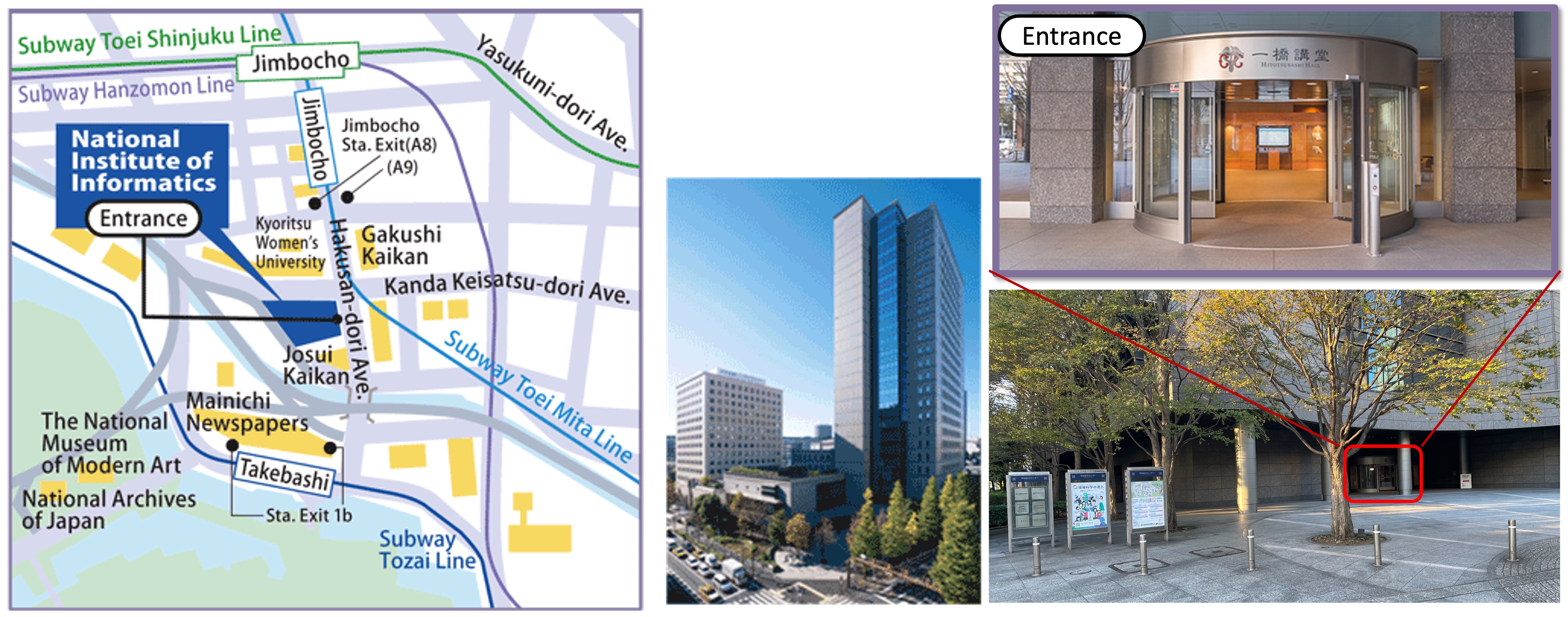
Lunch Map
Please refer to this link for the lunch map. (More restaurants can be easily found using a Google map)
Lunch is not provided. There are over 100 restaurants in the area, so please enjoy yourselves.
Organizers (in alphabetical order)
- Jean-Francois Bonastre - Inria and Avignon University, France
- Erica Cooper - NII, Japan
- Nicolas Evans - EURECOM, France
- Xuechen Liu - NII, Japan
- Xiaoxiao Miao - NII, Japan
- Massimiliano Todisco - EURECOM, France
- Xin Wang - NII, Japan
- Junichi Yamagishi - NII, Japan
- Chang Zeng - NII, Japan
Acknowledgement
This workshop is partially supported by Japan Science and Technology Agency (JST).